

1. 그룹함수
- 여러행에서 하나의 결과값을 꺼내는 함수
- AVG, SUM, MIN, MAX, COUNT
- 날짜에 대해서도 MIN, MAX 값 구할 수 있음
ex) 첫 로그인 날짜, 마지막 로그인 날짜 - 주의! 그룹함수가 일반 컬럼과 동시에 출력 불가 (데이터 베이스별로 다름)
ex) select employee_id, sum(salary) from employees; → error! - group by에 묶인 절들만 select에 쓸 수 있음
COUNT(*) : null값을 포함하는 행을 포함한 행의 수
COUNT(column) : null값은 제외한 행의 개수
count(*) over() -- 전체행 수 (잘못쓰면 느려짐, 그룹핑으로 안 묶여도 사용가능)
count안에 distinct 붙이면 유일한 값이 나오므로 부서번호는 종류별로 나타낼 수 있음
select count(distinct employee_id) from employees;
1.1. Group by - Having
where절 / group by / order절
- 여러행에서 특정 그룹별로 집계를 구할 때
ex) 같은 부서들끼리 묶을 때 - group by 2개, 3개까지 가능 / ,찍고 나열 (보통 2개, 순차적으로 그룹핑됨)
1.1.1. Having
- group by절의 조건
- where절에는 그룹함수 사용 불가, where은 열 정렬(order절)에 관한 일반 조건
1.2. Rollup, Cube, Grouping
- 시험에 자주 등장
- rollup - select된 데이터와 그 데이터의 총계를 구함
- cube - 구할 수 있는 모든 그룹의 총계, 소계 (서브 그룹까지 다 나옴)
- grouping
해당 row가 결과집합에 의해 산출된 데이터인지? 0
rollup이나 cube에 의해 산출된 데이터(가짜)인지? 1
decode 사용시 null값이면 null을 넣는게 아니고 1을 넣어줘야 함
2022.11.09 - [프로그래밍 언어/SQL] - [SQL] SQL 함수
1.2.1. 실습
<java />
-- 그룹 함수 AVG, MAX, MIN, SUM, COUNT
select avg(salary), max(salary), min(salary), sum(salary), count(*) from employees;
select max(hire_date), min(hire_date) from employees;
-- count(*), count(컬럼)
select count(*) from employees; -- 총 행 데이터의 수
select count(commission_pct), count(manager_id) from employees; -- null이 아닌 행의 수
-- 주의할 점: 그룹함수가 일반 컬럼과 동시에 출력 불가
select employee_id, sum(salary) from employees;
-- group by
select department_id, job_id, sum(salary) from employees group by department_id, job_id ;
------------------------------------------------------------------------------
-- 부서별 급여평균
select department_id, avg(salary) from employees group by department_id;
-- group절엠 묶이지 않은 컬럼은 select 절에 사용불가 (데이터 베이스별로 다름)
select job_id, department_id from employees group by department_id;
-- 2개 이상의 그룹핑
SELECT
department_id,
job_id,
SUM(salary),
COUNT(*), -- 그룹별 수
count(*) over() -- 전체행 수
FROM
employees
GROUP BY
department_id,
job_id
ORDER BY
department_id DESC;
select department_id, job_id, count(*) over() -- 전체행 수 (그룹핑으로 안 묶여도 사용가능)
from employees;
-- where절에 그룹함수 사용불가
select department_id from employees where sum(salary) >= 5000 group by department_id;
---------------------------------------------------------------------------------
-- having (그룹의 조건)
select department_id, sum(salary) from employees group by department_id having sum(salary) > 100000;
select job_id, count(*) from employees group by job_id having count(*) >= 20;
-- 부서 아이디가 50이상인 것들을 그룹화 시키고, 그룹평균 중 5000 이상만 조회, 정렬 평균(salary) 내림차순
SELECT
department_id,
trunc(AVG(salary)) AS 평균
FROM
employees
WHERE
department_id >= 50
GROUP BY
department_id
HAVING
AVG(salary) >= 5000
ORDER BY
평균 DESC;
-- 직무 SA가 포함된 데이터의 그룹별 사원수, 그룹별 급여합
select job_id, count(*) as 사원수, sum(salary) as 급여합 from employees where job_id like '%SA%' group by job_id;
-------------------------------------------------------------------------------------------------
-- 롤업: 주 그룹의 토탈
-- 그룹핑 1개 → 총계 출력
select department_id, sum(salary) from employees group by rollup(department_id) order by department_id;
-- 그룹핑 2개 → 총계와 주그룹의 토탈
select department_id, job_id, avg(salary), count(salary) from employees group by rollup(department_id, job_id) order by department_id, job_id;
-- 큐브: 서브 그룹의 토탈
select department_id, job_id, avg(salary), count(salary) from employees group by cube(department_id, job_id) order by department_id, job_id;
-- grouping
select department_id, decode( grouping(job_id), 1, '소계', job_id ), avg(salary), count(salary), grouping(job_id), grouping(department_id)
from employees
group by rollup(department_id, job_id)
order by department_id, job_id;
grouping 문제
<sql />
-- 문제1 order by sum(salary)
select job_id, count(*) as 사원의수, avg(salary) as 월급평균 from employees group by job_id order by 월급평균 desc;
-- 문제2 hire_date는 date형 / 입사년도 별 사원수!!!!!!!!!!!
select substr(hire_date,1,2) as 입사년도, count(*) as 사원의수 from employees group by substr(hire_date,1,2);
select to_char(hire_date, 'yy') as 입사년도, count(*) as 사원의수 from employees group by to_char(hire_date, 'yy');
-- 문제3
select department_id, avg(salary) from employees where salary >= 1000 group by department_id having avg(salary) >= 2000;
-- 문제4
select department_id, trunc(avg(commission_pct * salary + salary), 2) as 평균, sum(commission_pct * salary + salary) as 합계, count(*)
from employees
where commission_pct is not null
group by department_id;
-- 문제5
select decode( grouping (job_id), 1, '합계', job_id ) as job_id,
sum(salary)
from employees
group by rollup(job_id)
order by job_id asc;
--문제6
select decode( grouping(department_id), 1, '합계', department_id) as department_id,
decode( grouping(job_id), 1, '소계', job_id) as job_id,
count(*) as total,
sum(salary) as sum
from employees
group by rollup(department_id, job_id)
order by sum asc;
-- 문제2 hire_date는 date형 / 입사년도 별 사원수!!!!!!!!!!!
select substr(hire_date,1,2) as 입사년도, count(*) as 사원의수 from employees group by substr(hire_date,1,2);
select to_char(hire_date, 'yy') as 입사년도, count(*) as 사원의수 from employees group by to_char(hire_date, 'yy');
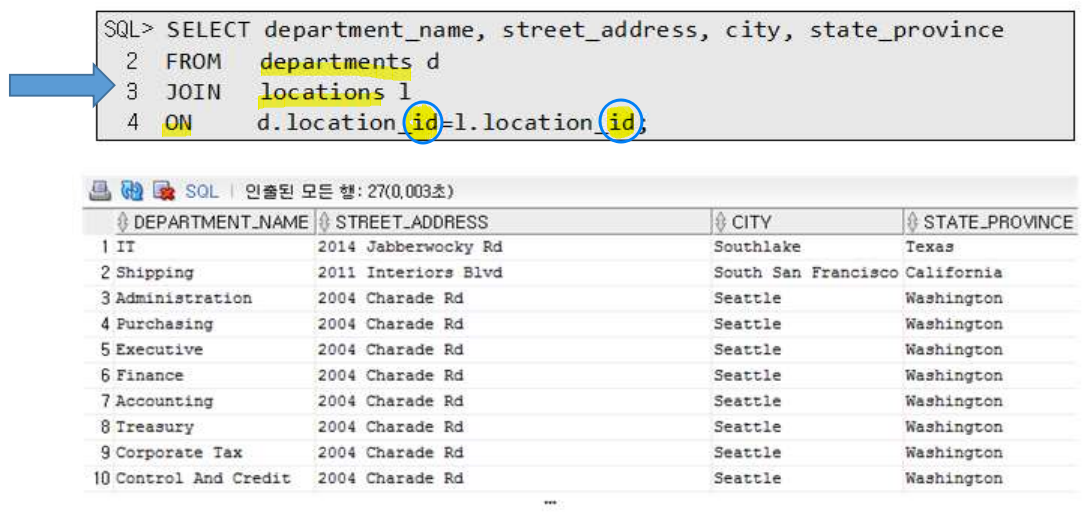
2. ★★★ Join ★★★
- 두 개의 테이블(연관되어 있는)을 조회하여 다시 하나로 합치는 것
여러개 사용 가능! - 조인의 종류
오라클 조인 - 나중에 확인
ANSI 조인

auth_id는 양쪽 테이블이 존재하기 때문에 [테이블.컬럼명]으로 지정해야 함
using (키)를 통한 조인
select * from info i inner join auth a using(auth_id);
2.1. Inner join
- 내부조인, join 앞 inner 생략 가능
- null값 X
2.2. Outer join
2.2.1. left outer
- 왼쪽에 다 붙여놓고 조인
2.2.2. right outer
- 오른쪽에 다 붙여놓고 조인
2.2.3. full outer
- 유실없이 전부 나옴
<sql />
--테이블생성
CREATE TABLE INFO
(
ID NUMBER NOT NULL
, TITLE VARCHAR2(100)
, CONTENT VARCHAR2(100)
, REGDATE DATE DEFAULT sysdate NOT NULL
, CONSTRAINT INFO_PK PRIMARY KEY
(
ID
)
ENABLE
);
CREATE TABLE auth
(
AUTH_ID NUMBER NOT NULL
, NAME VARCHAR2(30)
, JOB VARCHAR2(30)
, CONSTRAINT TABLE1_PK PRIMARY KEY
(
AUTH_ID
)
ENABLE
);
--시퀀스 생성
CREATE SEQUENCE SEQ_INFO;
CREATE SEQUENCE SEQ_AUTH;
--데이터 삽입
INSERT INTO info(id, title, content) VALUES(SEQ_INFO.nextval, 'java', 'java is');
INSERT INTO info(id, title, content) VALUES(SEQ_INFO.nextval, 'jsp', 'jsp is');
INSERT INTO info(id, title, content) VALUES(SEQ_INFO.nextval, 'spring', 'spring is');
INSERT INTO info(id, title, content) VALUES(SEQ_INFO.nextval, 'oracle', 'oracle is');
INSERT INTO info(id, title, content) VALUES(SEQ_INFO.nextval, 'mysql', 'mysql is');
INSERT INTO info(id, title, content) VALUES(SEQ_INFO.nextval, 'c', 'c is');
INSERT INTO auth(auth_id, name, job) values(SEQ_AUTH.nextval, '박인욱', 'developer');
INSERT INTO auth(auth_id, name, job) values(SEQ_AUTH.nextval, '홍길자', 'DBA');
INSERT INTO auth(auth_id, name, job) values(SEQ_AUTH.nextval, '이순신', 'designer');
INSERT INTO auth(auth_id, name, job) values(SEQ_AUTH.nextval, '고길동', 'scientist');
INSERT INTO auth(auth_id, name, job) values(SEQ_AUTH.nextval, '박인욱', 'teacher');
--------------------------------------------------------------------------------------
select * from info;
select * from auth;
-- Inner Join
select * from info inner join auth on info.auth_id = auth.auth_id; -- null값 X
select * from info left outer join auth on info.auth_id = auth.auth_id; -- 왼쪽 테이블 전체에 오른쪽 붙임
select * from auth right outer join info on auth.auth_id = info.auth_id;
select * from info right outer join auth on info.auth_id = auth.auth_id; -- 오른쪽 테이블 전체에 왼쪽 붙임
select * from info full outer join auth on info.auth_id = auth.auth_id; -- 유실없이 전부 나옴
select * from info cross join auth; -- 잘못된 형태의 join
-- auth_id는 양쪽 테이블이 존재하기 때문에 [테이블.컬럼명]으로 지정해야 함
select id, title, info.auth_id, name, job
from info inner join auth on info.auth_id = auth.auth_id;
-- 테이블 엘리어스를 이용한 조인
select i.title, i.regdate, i.auth_id, name
from info i inner join auth a on i.auth_id = a.auth_id;
-- 조건
select *
from info i inner join auth a on i.auth_id = a.auth_id
where i.auth_id = 1;
-- using (키)를 통한 조인
select * from info i inner join auth a using(auth_id);
-- 여러 데이터를 조인
select * from employees;
select * from departments;
select * from locations;
select * from employees e
left outer join departments d on e.department_id = d.department_id
left outer join locations l on d.location_id = l.location_id;
-- self join (하나의 테이블로 조인)
-- 일단 left join이기 때문에 manager_id가 없는 steven도 나옴
select nvl(e2.first_name, '없음') as 상사, e1.first_name as 직원
from employees e1
left outer join employees e2
on e1.manager_id = e2.employee_id
order by e1.employee_id;
-- 앞이 상사, 뒤가 직원 / 카테고리 같은 곳, 계단형 형식에 쓰임, 여러 테이블을 사용하는게 아니라 self join 이용
-----------------------------------------------------------------------------------------------------------------------------
-- 오라클 조인 (오라클만 사용하는 문법)
-- inner join
select * from employees e, departments d -- 조인테이블
where e.department_id = d.department_id; -- 조인키
-- left outer join
select * from employees e, departments d -- 조인테이블
where e.department_id = d.department_id(+); --조인키, 오른쪽에 있는 것을 왼쪽에 붙이겠다.
-- right outer join
select * from employees e, departments d
where e.department_id(+) = d.department_id -- 왼쪽에 있는 것을 오른쪽에 붙이겠다.
and employee_id is null; -- 조건은 and로!
2.3. Closs join
- 잘못된 형태의 join
2.4. Self join
- 나의 테이블에 다시 나의 테이블을 붙이는 조인
aka.하나의 테이블로 조인 - 내 테이블에 내가 연결된 KEY가 있어야 함
- 앞이 상사, 뒤가 직원 / 카테고리 같은 곳, 계단형 형식에 쓰임, 여러 테이블을 사용하는게 아니라 self join 이용
2.5. 추가
2.5.1. 1. join ~ on 절을 반복적으로 사용 - 3개 이상 테이블에서 가능
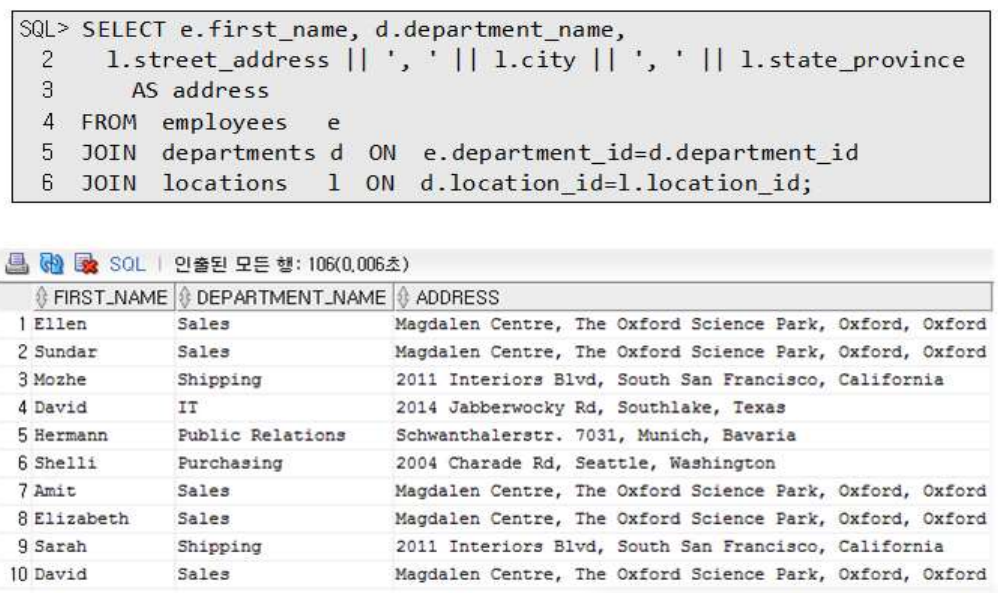
2.5.2. 2. 조인 조건과 where절 조건을 분리해서 작성
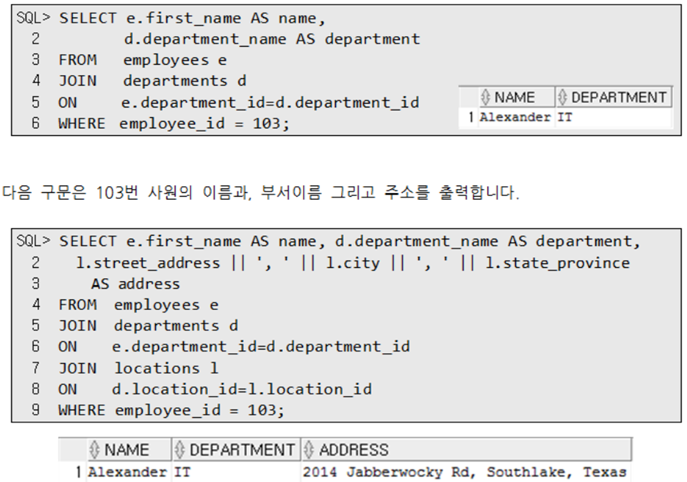
2.5.3. 3. 일반 조건을 반드시 where에 적지 않아도 됨

2.5.4. 4. 조인 실습파일
<sql />
-- 문제1
select * from employees e inner join departments d on e.department_id = d.department_id;
select * from employees e left outer join departments d on e.department_id = d.department_id;
select * from employees e right outer join departments d on e.department_id = d.department_id;
select * from employees e full outer join departments d on e.department_id = d.department_id;
-- 문제2
select (first_name || ' ' || last_name) as name, d.department_name
from employees e
inner join departments d
on e.department_id = d.department_id
where employee_id = 200;
-- 문제3
select (first_name || last_name) as name, e.job_id, j.job_title
from employees e
inner join jobs j
on e.job_id = j.job_id
order by name asc;
-- 문제4
select * from jobs j left outer join job_history h on j.job_id = h.job_id;
-- 문제5
select (first_name || last_name) as name, job_id from employees where first_name = 'Steven' and last_name = 'King';
select (first_name || last_name) as name from employees e
left outer join departments d
on e.department_id = d.department_id
where e.first_name = 'Steven' and e.last_name = 'King';
-- 문제6 이름, 부서id, 부서 이름까지 뽑기
select * from employees cross join departments;
-- 문제7
select employee_id as 사원번호, (first_name || last_name) as 이름,
salary as 급여, department_name as 부서명, d.location_id as 근무지, l.street_address
from employees e
left join departments d on e.department_id = d.department_id
left join locations l on d.location_id = l.location_id
where e.job_id = 'SA_MAN';
-- 문제8
select *
from employees e
inner join jobs j
on e.job_id = j.job_id
where job_title = 'Stock Manager' or job_title = 'Stock Clerk';
-- 문제9 -null인 부서
select * from departments d
left outer join employees e
on d.department_id = e.department_id
where e.employee_id is null;
-- 문제10
select e1.first_name as 사원이름, e2.first_name as 매니저이름
from employees e1
inner join employees e2 -- inner join해서 상사 없는 steven이 안나옴
on e1.manager_id = e2.employee_id
order by e1.employee_id;
-- 문제11 -다시 확인
select e1.employee_id,
e1.first_name,
e1.manager_id,
e1.job_id,
e1.salary,
e2.employee_id,
e2.manager_id as 매니저,
e2.first_name as 매니저이름,
e2.salary as 매니저급여
from employees e1
left outer join employees e2
on e1.manager_id = e2.employee_id
order by salary desc;
-- 힌트 self join 2번, case when then
select e2.first_name, e1.first_name
from employees e1
left outer join employees e2
on e1.manager_id = e2.employee_id
order by e1.employee_id;
-- 문제9. department 테이블에서 직원이 없는 부서를 찾아 출력
select * from departments d
left outer join employees e
on d.department_id = e.department_id
where e.employee_id is null;
-- 문제11. 10번 변형, EMPLOYEES 테이블에서 left join하여 관리자(매니저)와, 매니저의 이름, 매니저의 급여 까지 출력하세요, 매니저 아이디가 없는 사람은 배제하고 급여는 역순으로 출력
select e1.employee_id,
e1.first_name,
e1.manager_id,
e1.job_id,
e1.salary,
e2.employee_id,
e2.manager_id as 매니저,
e2.first_name as 매니저이름,
e2.salary as 매니저급여
from employees e1
left outer join employees e2
on e1.manager_id = e2.employee_id
order by salary desc;
오늘 하루
기억에 남는 부분
-
-
어려운 부분
-
-
문제 해결 부분
-
-
'프로그래밍 언어 > SQL-Oracle' 카테고리의 다른 글
| [SQL] DML 데이터조작어(insert, update, delete, merge, ctas), TCL(트랜잭션) (0) | 2022.11.15 |
|---|---|
| [SQL] 서브쿼리(단일행, 다중행, 스칼라), 인라인뷰, rownum (0) | 2022.11.11 |
| [SQL] SQL 함수 (문자, 숫자, 날짜, 형변환, 집합, 분석) (0) | 2022.11.09 |
| [SQL] SQL (select, 조건절, 연산자) (0) | 2022.11.08 |
| [SQL] RDBMS 데이터베이스, oracle SQL developer (0) | 2022.11.08 |
