
728x90

1. DML (Data Manipulation Language)
- select(포함) 다음으로 중요
- DML 문장은 실수했을 때 반영하겠다는 commit 전 rollback으로 복구 가능
- 트랜잭션: 작업의 논리적인 단위 형태인 DML 문장의 모음으로
트랜잭션을 완료 시켜야 원본 데이터에 반영됨
desc departments; -- 요약
select * from departments; -- 테이블 확인
rollback; -- 되돌리기
1.1. Insert
- 행을 추가
- desc 테이블명; - 열 확인 가능
not null = null값이 들어가면 안됨 - 모든 컬럼을 다 사용하면 컬럼부분 생략 가능
순서와 타입에 맞게 모든 열들에 대한 입력정보가 포험되어 있어야 함
1.1.1. insert 방법1. values ( )에 직접 값 삽입
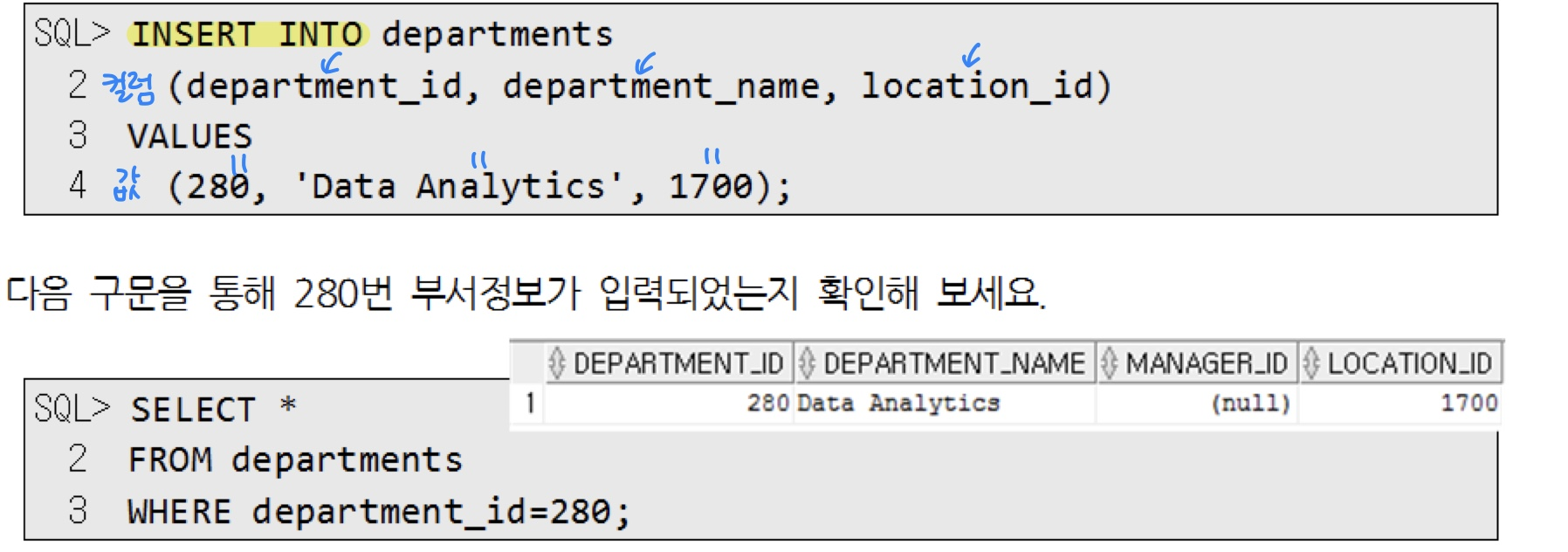
1.1.2. insert 방법2. sub query 사용 (values 대신)


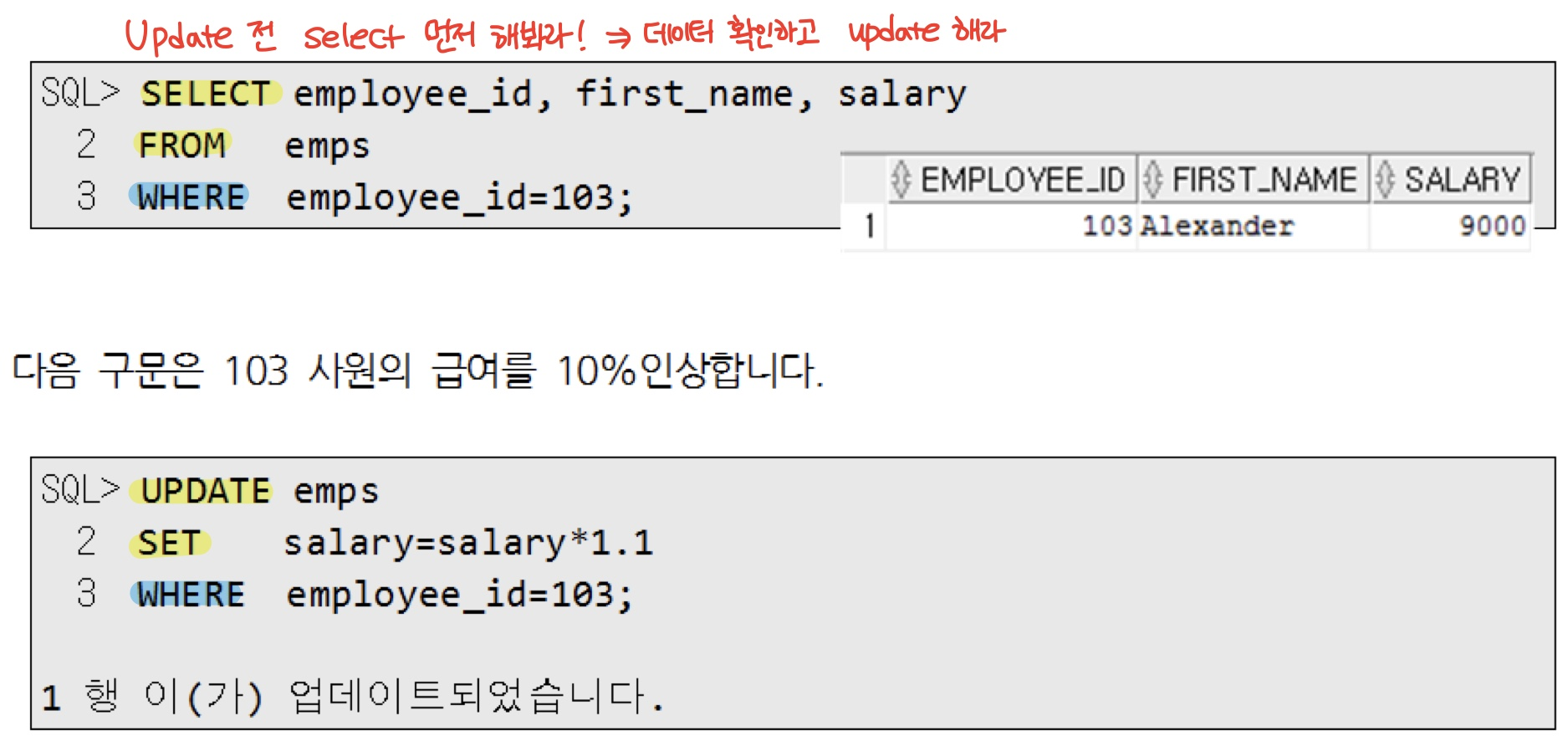
1.2. Update - set
- 기존의 행을 변경
- Update 전 select로 변경 전 데이터 확인
- where 조건 필수
조건이 바뀌면 다 바뀌기 때문에 꼭 특정 행 명시
PK는 업데이트 X
select는 데이터를 찾아낸 순서 = 조회된 순서일 뿐
key - pk 기준으로 조회 (예제에는 인덱스라는 개념이 같이 들어가 있기 때문)

1.2.1. update 방법1. update - set - where
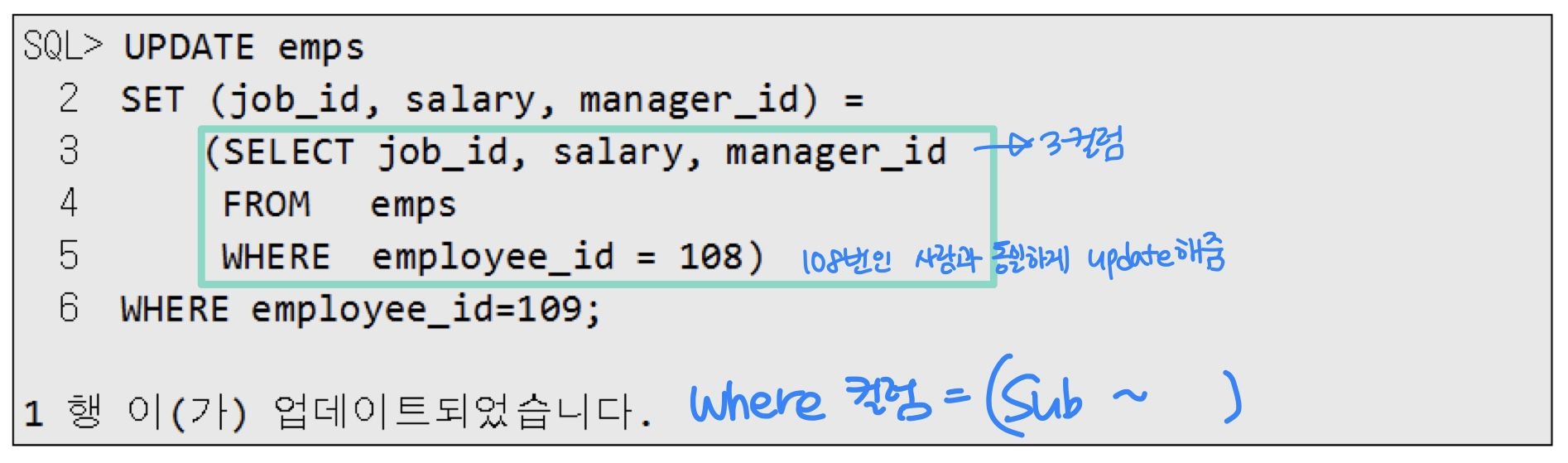
1.2.2. update 방법2. sub query 사용 (values 대신)

1.3. Delete
- 기존의 행을 제거
- 행 삭제는 실행하기 전에 반드시 확인하는 습관을 가져야 함
- 웬만하면 KEY로 지우고, 서브쿼리 같은거 쓸 생각 X


실습
더보기
<sql />
-- insert
desc departments; -- 요약
-- 1st
insert into departments values (280, '개발자', null, 1700);
-- 2st
insert into departments(department_id, department_name, location_id) values(290, 'DBA', 1700);
select * from departments; -- 테이블 확인
rollback; -- 되돌리기
-- 예제 값 넣기
insert into departments(department_id, department_name, manager_id, location_id)
values (290, '디자이너', null, 1700);
insert into departments(department_id, department_name, manager_id, location_id)
values (300, 'DB관리자', null, 1800);
insert into departments(department_id, department_name, manager_id, location_id)
values (310, '데이터분석가', null, 1800);
insert into departments(department_id, department_name, manager_id, location_id)
values (320, '퍼블리셔', 200, 1800);
insert into departments(department_id, department_name, manager_id, location_id)
values (330, '서버관리자', 200, 1800);
select * from departments; -- 테이블 확인
rollback; -- 되돌리기
-- 실습을 위한 사본테이블
create Table emps as (select * from employees where 1 = 2); -- 구조만 복사
select * from emps; -- 데이터는 없고 컬럼은 복사됨
-- 3nd (서브쿼리절) - values를 서브쿼리절로 대체
insert into emps (select * from employees where job_id = 'IT_PROG');
--
desc emps;
insert into emps (employee_id, first_name, last_name, email, hire_date, job_id)
(select employee_id, first_name, last_name, email, hire_date, job_id from employees where job_id = 'FI_MGR'); -- 서브쿼리절
--
insert into emps (employee_id, first_name, last_name, email, hire_date, job_id)
values ( (select max(employee_id) + 100 from emps), 'test', 'test', 'test', sysdate, 'test'); -- emps의 max값 + 100을 employee_id에 넣음
--------------------------------------------------------------------------------------------------------------------------------------
commit;
-- update
select * from emps; -- 테이블 확인
update emps set salary = 10000; -- 조건절X, 이렇게 하면 큰일남
update emps set salary = 10000 where employee_id = 103; -- 조건은 KEY를 이용하면 됨
update emps set salary = salary * 1.1 where employee_id = 103;
update emps set phone_number = '523.123.4567', manager_id = 102 where employee_id = 103; -- 여러 컬럼일 경우 ,(콤마)로 나열
-- update 서브쿼리
update emps set salary = (select salary from emps where employee_id = 104) where employee_id = 103; -- 103의 salary가 104와 똑같이 바뀜
update emps set (salary, phone_number) = (select salary, phone_number
from emps
where employee_id = 104)
where employee_id = 103; -- 103의 salary와 phone_number가 104와 똑같이 바뀜
update emps set commission_pct = 0.2 where department_id = (select department_id from emps where first_name = 'Diana');
------------------------------------------------------------------------------------------------------------------------------------
-- delete
delete from emps where employee_id = 208; -- KEY를 이용한 삭제
delete from emps where job_id = 'FI_MGR'; -- key 사용 안해도 지워지기는 함, 비추천
-- delete 서브쿼리
delete from emps where department_id = (select department_id from emps where first_name = 'Diana');
select * from departments; -- pk = department_id
select * from employees;
delete from departments where department_id = 50; -- fk로 사용되는 pk는 안 지워짐
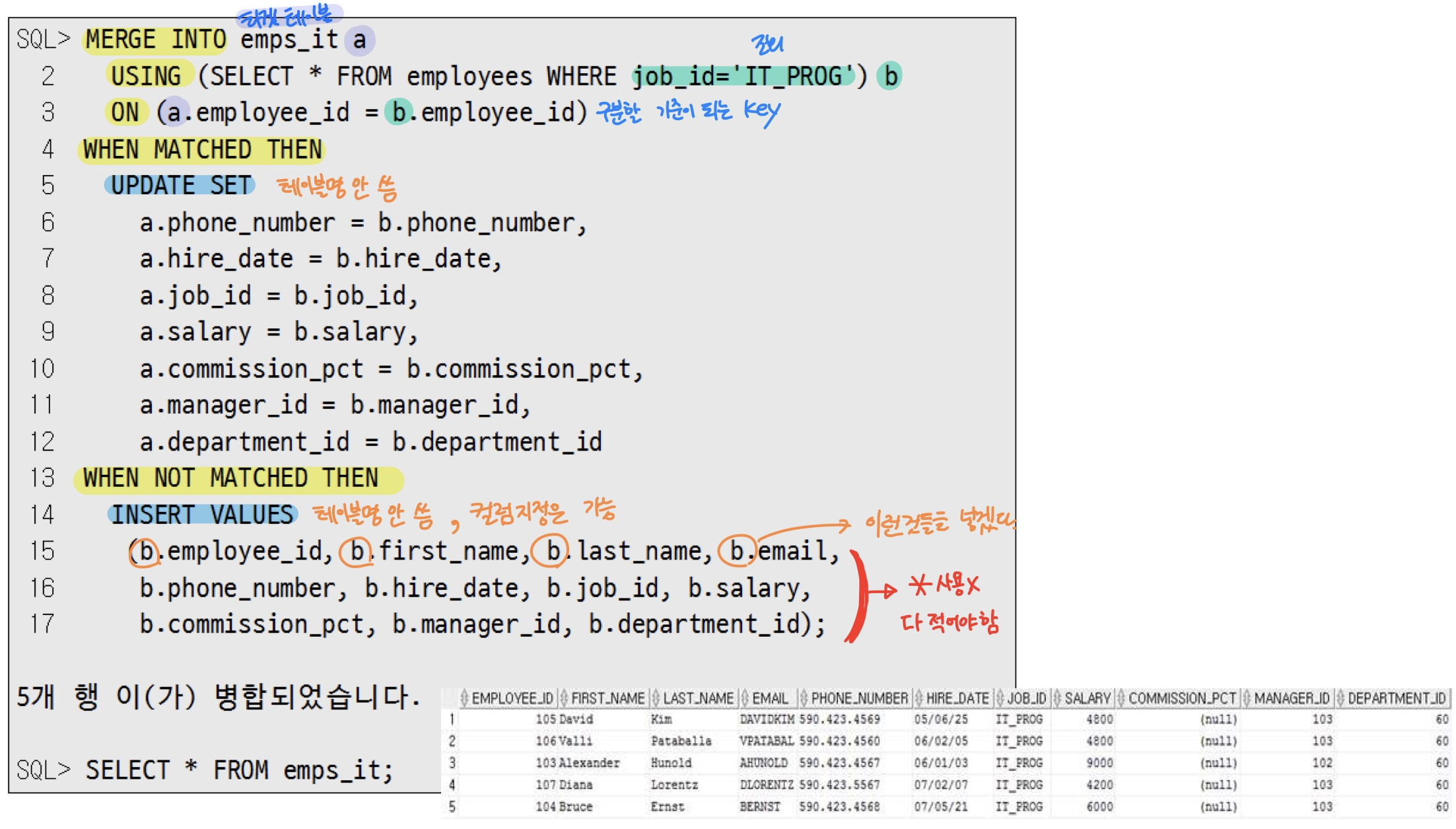
1.4. Merge
- 병합
- 중요한 테이블이 있고, 매번 탈퇴, 수정되는 데이터를 따로 저장하는 테이블을 만들어놓고, 일주일 단위로 업데이트
- 데이터 존재 여부 체크
↓
존재하면 update
존재하지 않으면 insert

1.4.1. 1. 동일한 테이블 구조를 가지고 있는 emps_it테이블로부터 데이터릉 옮기는 merge 구문
1.4.2. 2. 직접 값을 넣고자 Dual 사용
다른 테이블에서 데이터를 비교하여 가져오는 것 X

1.5. Ctas (사본 테이블)
- Create table as select
- 같은 테이블 혹은 같은 구조를 갖는 테이블 생성
not null 제약조건을 제외한 다른 제약조건은 복사되지 X
create table 사본테이블 이름 as (select * from 복사할 테이블); -- 테이블 복사
create table 사본테이블 이름 as (select * from 복사할 테이블 where 1 = 2); -- 구조 복사
실습
더보기
<sql />
rollback;
select * from emps; -- 테이블 확인
delete from emps where employee_id in(104, 105, 106, 107, 108, 208); -- 103번 빼고 삭제
-- merge (있으면 업데이트, 없으면 인서트)
select * from employees where job_id = 'IT_PROG';
-- 동일한 형식의 merge 구문
merge into emps a -- 타겟 테이블
using (select * from employees where job_id = 'IT_PROG') b -- 조인구문 (적용할 테이블), 조건이 없으면 employees 테이블 다 들어옴
on (a.employee_id = b.employee_id) -- 조인조건 (KEY)
when matched then -- 조건에 일치할 경우 타겟 테이블에 실행
update set
a.phone_number = b.phone_number,
a.hire_date = b.hire_date,
a.salary = b.salary,
a.commission_pct = b.commission_pct,
a.manager_id = b.manager_id,
a.department_id = b.department_id
when not matched then -- 조건에 일치하지 않는 경우 타겟 테이블에 실행
insert values -- 컬럼만 지정도 가능
(b.employee_id, b.first_name, b.last_name,
b.email, b.phone_number, b.hire_date, b.job_id,
b.salary, b.commission_pct, b.manager_id, b.department_id); -- insert는 *가 없음
-- 다른 테이블에서 데이터를 비교하여 가져오는 것이 아니라, 직접 값을 넣고자 한다면 dual을 사용
-- 단, on절 은 키를 통한 연결이 들어가야 함
merge into emps a
using dual
on (a.employee_id = 1000)
when matched then
update set first_name = 'test1',
last_name = 'test2'
when not matched then
insert (employee_id,
first_name,
last_name,
email,
hire_date,
job_id)
values (1000, 'ADMIN1', 'ADMIN2', 'ADMIN', sysdate, 'ADMIN');
문제
<sql />
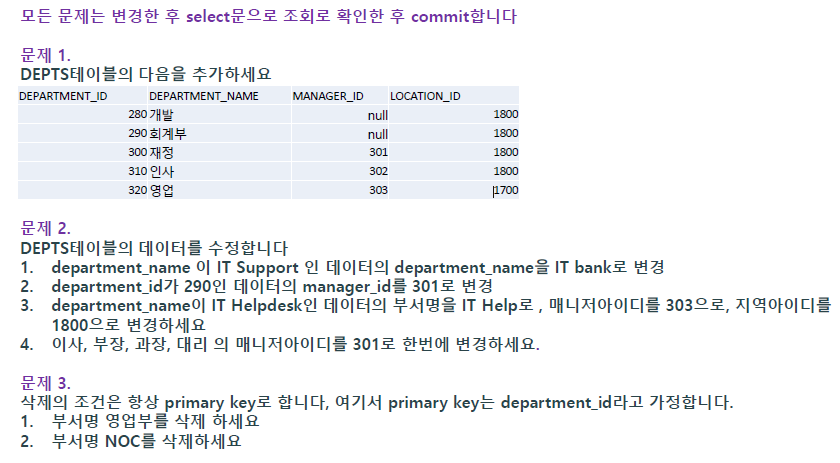
-- 문제1
create table depts as (select * from departments); -- 테이블 복사
create table depts as (select * from departments where 1 = 2); -- 구조 복사
select * from depts; -- 테이블 확인
rollback;
insert into depts values (280, '개발', null, 1800);
insert into depts values (290, '회계부', null, 1800);
insert into depts values (300, '재정', 301, 1800);
insert into depts values (310, '인사', 302, 1800);
insert into depts values (320, '영업', 303, 1700);
commit;
-- 문제2
update depts
set department_name = 'IT Bank'
where department_name = 'IT Support';
commit;
update depts
set manager_id = 301
where department_id = 290;
commit;
update depts
set department_name = 'IT Help', manager_id = 303, location_id = 1800
where department_name = 'IT Helpdesk';
commit;
update depts
set manager_id = 301
where department_id in (290, 300, 310, 320);
commit;
-- 문제3
delete from depts
where department_id = 320; -- 영업부 = 320 삭제
commit;
delete from depts
where department_id = 220; -- NOC = 220 삭제
commit;
-- 문제4
--insert into emps (employee_id, first_name, last_name, email, hire_date, job_id)
--values ( (select max(employee_id) + 100 from emps), 'test', 'test', 'test', sysdate, 'test'); -- emps의 max값 + 100을 employee_id에 넣음
delete from depts
where department_id > 200;
commit;
update depts
set manager_id = 100
where manager_id is not null;
commit;
merge into depts a -- 타겟테이블 depts
using (select * from departments) b -- departments 테이블 전체 조회
on(a.department_id = b.department_id) -- 구분할 기준이 되는 key
when matched then -- 존재하는 경우
update set
a.department_name = b.department_name,
a.manager_id = b.manager_id,
a.location_id = b.location_id
when not matched then -- 존재하지 않는 경우
insert values
(b.department_id, b.department_name, b.manager_id, b.location_id);
commit;
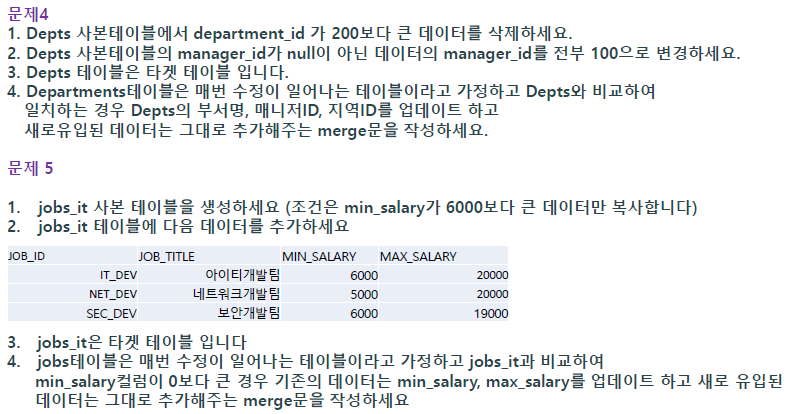
-- 문제6
create table jobs_it as (select * from jobs where min_salary > 6000); -- 테이블 복사, 조건있음
commit;
insert into jobs_it values('IT_DEV', '아이티개발팀', 6000, 20000);
insert into jobs_it values('NET_DEV', '네트워크개발팀', 5000, 20000);
insert into jobs_it values('SEC_DEV', '보안개발팀', 6000, 19000);
commit;
merge into jobs_it a
using (select * from jobs) b
on(a.job_id = b.job_id)
when matched then
update set
a.min_salary = b.min_salary,
a.max_salary = b.max_salary
when not matched then
insert values
(b.job_id, b.job_title, b.min_salary, b.max_salary);
commit;
2. 트랜잭션
- 논리의 작업단위
- DML 작업에만 트랜잭션 유효
- 사용자의 데이터베이스 종료 또는 시스템 충돌에 의한 데이터베이스 비정상적 종료에 의해 트랜잭션이 종료되어 변경사항이 취소될 수 있음
- 트랜잭션을 실행 가능한 SQL 문장이 제일 처음 실행될 때 시작
2.1. commit
- 미결정 데이터를 영구적으로 변경함으로써 현재 트랜잭션 종료
<sql />
-- 기본적으로 autocommit off; 임
set autocommit on; -- autocommit immediate
show autocommit;
set autocommit off; -- autocommit off
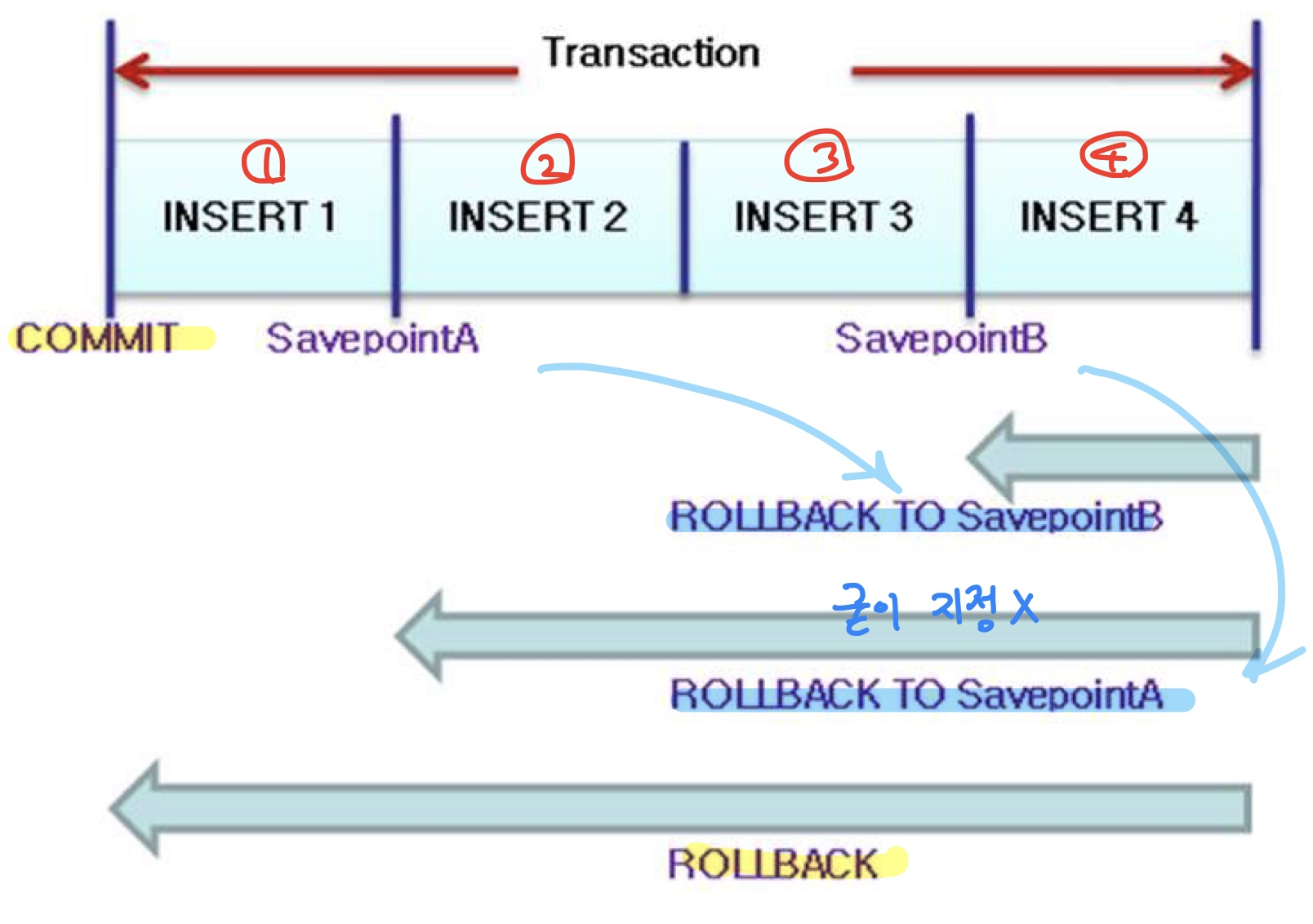
2.2. rollback
- 작업 취소
- rollback 할 위치 굳이 지정 안해줘도 됨
commit, rollback 장점
1. 일관성 제공
2. 데이터 변경을 미리보기
3. 작업을 논리적으로 그룹화
더보기
<sql />
-- 트랜잭션
-- commit, rollback;
-- 오토커밋 여부
show autocommit;
-- 오토커밋 on
set autocommit on;
set autocommit off;
select * from depts;
delete from depts where department_id = 10;
delete from depts where department_id = 20;
rollback; -- 마지막 commit 시점
commit;
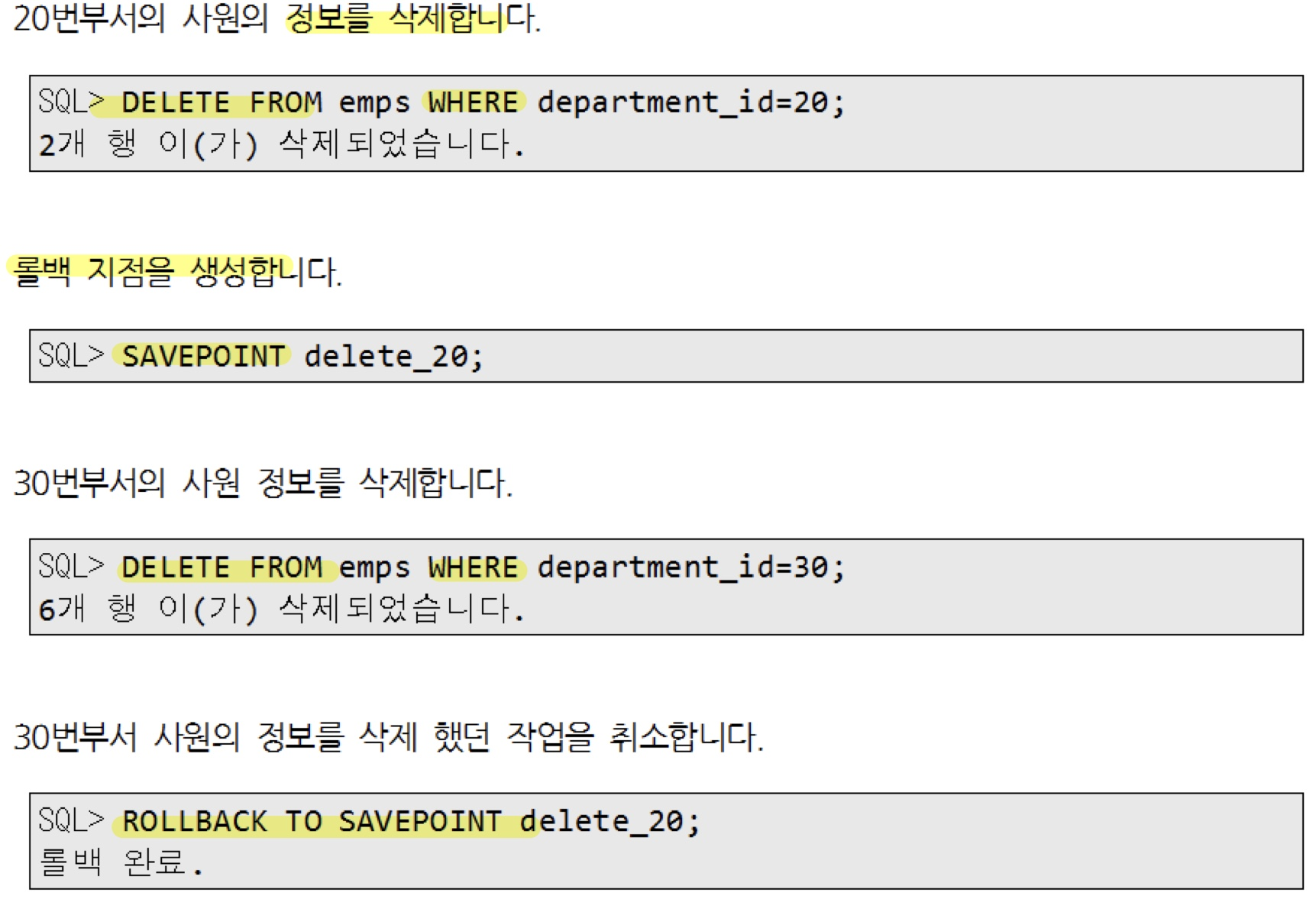
delete from depts where department_id = 10;
savepoint delete10;
delete from depts where department_id = 20;
savepoint delete20;
-- savepoint로 돌아가기
rollback to savepoint delete20;
rollback to savepoint delete10;
commit; -- 이전 시점으로 돌아가지 못함
-- 주문 결제 프로세스에서 사용
오늘 하루
더보기
기억에 남는 부분
- insert의 values 절에서 서브쿼리 사용 가능
- update - set, delete의 경우 wherer 조건이 필수
어려운 부분
- merge 구문이 길어서 기억하기 어려움, insert value에는 * 사용 못하고, 다 적어야 함
- dual 사용부분
문제 해결 부분
- 실습 문제 전부 해결
728x90
'프로그래밍 언어 > SQL-Oracle' 카테고리의 다른 글
| [SQL] 제약조건, view (0) | 2022.11.16 |
|---|---|
| [SQL] DDL 데이터 정의어, 테이블 CRUD (0) | 2022.11.15 |
| [SQL] 서브쿼리(단일행, 다중행, 스칼라), 인라인뷰, rownum (0) | 2022.11.11 |
| [SQL] 그룹함수 count(~별!), Join (inner,outer,cross,self) (0) | 2022.11.10 |
| [SQL] SQL 함수 (문자, 숫자, 날짜, 형변환, 집합, 분석) (0) | 2022.11.09 |
